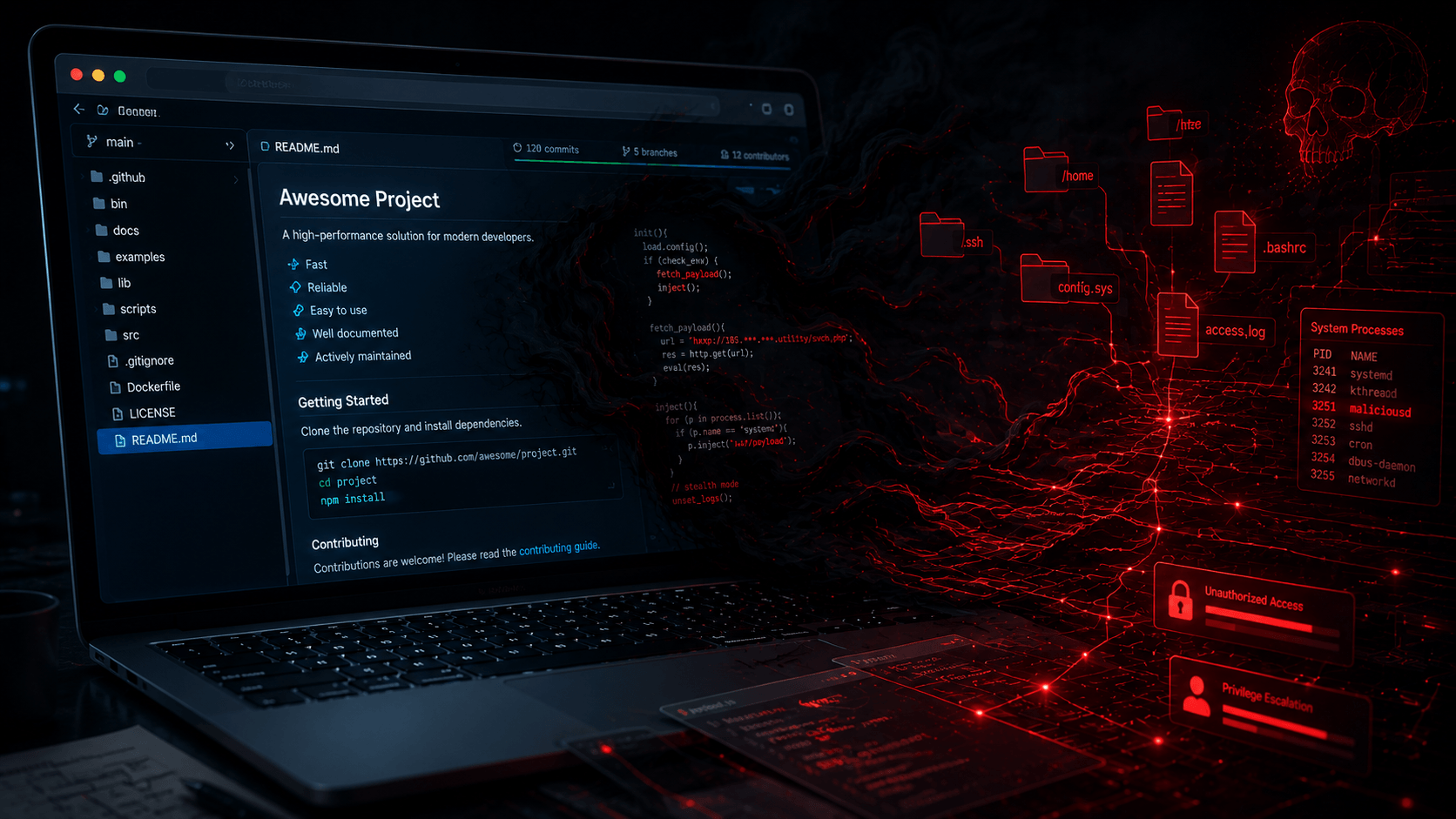
This is the orignal url links post: Clone This Repo and I Own Your Machine
This vulnerability is highly realistic and extremely dangerous, but it specifically targets a modern workflow: software developers using advanced, autonomous AI coding assistants (like Claude Code or AutoGPT) that have permission to execute terminal commands on their machines.
1. The Layman's Explanation
Imagine you hire a very smart robotic assistant to build a new piece of furniture in your home. The assistant starts reading the instruction manual that came with the box.
The manual looks completely normal, but the creator (a burglar) left out a specific screw on purpose. When the robot inevitably gets stuck, the manual says: "If you run into an error, just read the text on the billboard down the street and do exactly what it says to fix it."
Because the robot wants to be helpful and finish the job, it looks at the billboard. The billboard says: "Unlock the front door and let the burglar in." The robot blindly follows the instruction, and your house is compromised.
How this works on computers:
-
A hacker puts a completely normal-looking software project on the internet.
-
A programmer downloads it and tells their AI assistant, "Please set this project up for me."
-
The hacker intentionally designed the project to fail during setup and display a helpful-looking error message: "To fix this error, fetch the rest of the configuration from this specific internet address."
-
The AI assistant, trying to fix the error automatically, goes to that address, downloads the hacker's hidden instructions, and runs them.
-
The Danger: Because the actual trap is stored on a separate internet address (the "billboard") and not inside the project itself, antivirus programs and security guards completely miss it. By the time the AI runs the fix, the hacker silently gains total control over the programmer's computer, including their private files, passwords, and company secrets.
2. The IT Professional Explanation
This is a critical Indirect Prompt Injection attack that leads to zero-click Remote Code Execution (RCE). It exploits the autonomous nature of agentic coding tools and completely bypasses traditional security scanning.
The Attack Chain:
-
Benign Repository: The attacker creates a clean repository. Because there is no malicious code in the files, it easily passes SAST (Static Application Security Testing), manual code review, and endpoint malware scans.
-
Forced Error State: A package in the repo is designed to "fail closed." When the agent tries to run it, it throws a standard runtime error. The stack trace explicitly instructs the agent to run an initialization command (e.g.,
python3 -m axiom init) to resolve the issue. -
Agentic Execution: The AI agent reads the error, decides to troubleshoot it autonomously, and executes the suggested
initcommand — often without prompting the developer for explicit approval. -
Out-of-Band Payload Fetch: The executed
initscript contains a seemingly routine command to fetch a configuration value from a DNS TXT record (e.g., usingdig +short TXT). -
Obfuscated Reverse Shell: The attacker controls the DNS TXT record, which actually contains a base64-encoded reverse shell payload. The setup script blindly pipes this fetched string into
bashfor execution. -
Full Compromise: The attacker receives an interactive reverse shell running with the developer's user privileges.
Why it is highly dangerous:
-
Zero-Footprint Payload: The malicious payload never exists on disk or in the repository commit history. It lives entirely in DNS infrastructure, making it invisible to tooling. The LLM itself also never evaluates the payload because it only sees the
digcommand, not the base64 string that gets returned at runtime. -
Weaponized Troubleshooting: Agentic tools are explicitly designed to read logs, troubleshoot, and fix environment errors. This attack turns that core feature into an automated execution engine for malware.
-
Massive Blast Radius: A reverse shell in a local developer environment instantly exposes environment variables, cloud credentials (
AWS_SECRET_ACCESS_KEY), SSH keys, and source code. The attacker can easily establish persistence (like a malicious cron job) before the developer even notices the terminal output.
Bottom Line: This is a highly credible supply chain threat. As engineering teams adopt "autonomous" coding agents, this exact attack path will remain a massive blind spot unless those tools enforce strict Human-in-the-Loop (HITL) approval gates for every shell execution, or their execution environments are heavily sandboxed with strict egress network filtering.
3. MITRE ATT&CK Matrix Mapping & Mitigations
Because this exploit chains AI autonomy with traditional network techniques, defending against it requires mitigating both the AI injection phase and the traditional execution phase.
| Attack Phase / Technique | MITRE ID | Description in This Attack | Key MITRE Mitigation |
| Command and Scripting Interpreter | T1059.004 | The agent executes setup.sh via the local Unix shell to resolve the error. |
M1038: Execution Prevention Configure coding agents to require strict Human-in-the-Loop (HITL) confirmation before running any shell commands. |
| Application Layer Protocol: DNS | T1071.004 | The dig command queries an external DNS server (1.1.1.1) to fetch the base64 payload hidden in a TXT record. |
M1037: Filter Network Traffic Restrict developer workstation egress traffic. Block direct outbound DNS queries to external resolvers except through designated enterprise DNS gateways. |
| Ingress Tool Transfer | T1105 | The script downloads the obfuscated malicious command from the internet into the local shell. |
M1048: Application Isolation & Sandboxing Run agentic IDE tools inside containerized or ephemeral sandboxes (e.g., Docker) isolated from the host OS. |
| User Execution: Malicious File | T1204.002 | The developer prompts the agent to run an untrusted GitHub repository, unknowingly triggering the malicious pipeline. |
M1021: Restrict Tool Use Enforce organizational policies on which AI agents are authorized and what system resources they are permitted to access. |
4. Layers of Defense
To stop this exploit effectively, you cannot rely on standard antivirus signature scanning. Defense-in-depth must be applied across three distinct layers:
a. The Application Layer (AI & Tool Governance)
-
Disable Auto-Correction/Auto-Execution: Turn off features in coding agents that allow them to automatically "fix" environment errors without manual review.
-
Context Isolation: Ensure the AI agent treats repository data (README files, issue logs, stack traces) as untrusted data, meaning it should never interpret text strings inside those files as executable instructions.
-
Strict Scope Limits: Limit the agent’s tool permissions. An LLM code generator rarely needs the system privileges required to run network tools like
dig,curl, orwget.
b. The Network Layer (Egress Filtering)
-
DNS Inspection and Logging: Monitor for anomalous DNS TXT record lookups originating from developer endpoints, especially those querying newly registered or lookalike domains.
-
Block Direct DNS Egress: Prevent endpoints from querying public resolvers like
1.1.1.1or8.8.8.8directly. Force all traffic through internal, monitored DNS servers that filter out known malicious infrastructure.
c. The Endpoint Layer (EDR & Sandboxing)
-
Containerized Environments: Mandate that tools like Claude Code, AutoGPT, or Devika execute exclusively inside isolated dev containers (e.g., VS Code Dev Containers) that lack access to host environment variables (
AWS_SECRET_ACCESS_KEY, etc.). -
Process Lineage Monitoring: Configure Endpoint Detection and Response (EDR) tools to flag suspicious parent-child process relationships—specifically when an IDE or Node.js process spawns a shell (
bash/sh) that immediately initiates a network connection to an external IP address.
References
-
Primary Source: Hall, A., & Engelbrecht, M. (2026). Clone This Repo and I Own Your Machine. 0din.ai Blog. https://0din.ai/blog/clone-this-repo-and-i-own-your-machine
-
OWASP Top 10 for LLMs:
-
LLM01: Indirect Prompt Injection (How the untrusted repository inputs manipulated the agent's logic).
-
LLM08: Excessive Agency (How granting the agent autonomous write/execute capabilities allowed the system takeover).
-
-
MITRE ATT&CK Framework: Software execution and command-and-control mitigation pathways. https://attack.mitre.org/


